
Castle
Most generative models can produce plausible images. Far fewer can stay geometrically coherent across views. The central question is whether that coherence can be learned indirectly, not by supervising 3D, but by forcing the model to reconstruct the missing parts of multi-view observations.
TLDR
Keep some latent patches clean, corrupt the rest with diffusion noise, and train the model to recover the missing content from the visible context.
Processes both clean and noisy patches jointly, treating noise corrupted patches as masked.
Why this matters
It changes the objective from pure generation to structured completion. The model has to reason about correspondences, occlusions, and scene geometry to fill in what is missing.
What emerges
A single pretrained model that can handle arbitrary mask patterns at inference time, making it useful for novel-view synthesis, interpolation, and video editing with the same mechanism.
Training as masked denoising
Start from a video in latent space. Divide it into spacetime patches. Keep a small subset clean, aggressively corrupt the rest, and ask the model to predict the clean signal of the corrupted patches.
- Represent video as latent spacetime patches. The model operates on compact video tokens rather than raw pixels.
- Keep visible evidence clean. Context patches, such as the first frame, remain usable anchors for reconstruction.
- Corrupt most of the remaining volume. Heavy masking forces the model to infer structure from sparse observations.
- Denoise clean and noisy tokens together. The network learns completion as one joint reconstruction problem.
1
Mask by noising
Visible context is preserved as clean latent patches. Missing regions are represented as patches at nonzero diffusion timesteps rather than as hard blanks.
2
Force cross-view reasoning
Because the target patch often must be inferred from other frames, the model cannot succeed through local texture copying alone. It must internalize geometric structure.
3
Reuse the solver
At inference, arbitrary masks become a powerful interface: warped views, interpolated views, or tracked object boxes can all be treated as partially observed spacetime volumes to complete.
Why it is different from standard conditioning
A lot of inverse-problem pipelines bolt conditioning onto a generator. This approach instead bakes inversion directly into the training objective. The model is not merely conditioned on visible content but it is trained from the start to reconstruct under partial observability.
Conditioning-based baselines
Can struggle with large holes or irregular visible regions because the model architecture was not optimized around arbitrary sparse evidence.
Guidance-based baselines
Can be expensive and brittle when the observed region is tiny. Directly learning the completion distribution is a better fit for these tasks.
Single training objective, multiple test-time tasks

Novel-view synthesis
Estimate monocular depth from a single image, warp it along an arbitrary target camera path, and complete the disoccluded or uncertain regions. Geometry comes from warping while realism and consistency come from masked diffusion completion.
View interpolation
Keep the endpoints clean, initialize the middle frames with noise, and let the model synthesize the in-between views while respecting structure across time.
Consistent video editing
Edit the first frame, track the edited region through the clip, and inpaint that region in later frames. The model learns to propagate the modification while adapting it to viewpoint changes.
Correcting bad warps on the fly via stochastic conditioning
Monocular depth is imperfect. Warp-based renderings therefore contain broken boundaries, doubled structures, and inconsistent surfaces. A simple fix is to condition on clean patches early in sampling, then re-noise them beyond a threshold timestep and denoise everything jointly.
Once the conditioning becomes uncertain, stop treating it as ground truth.
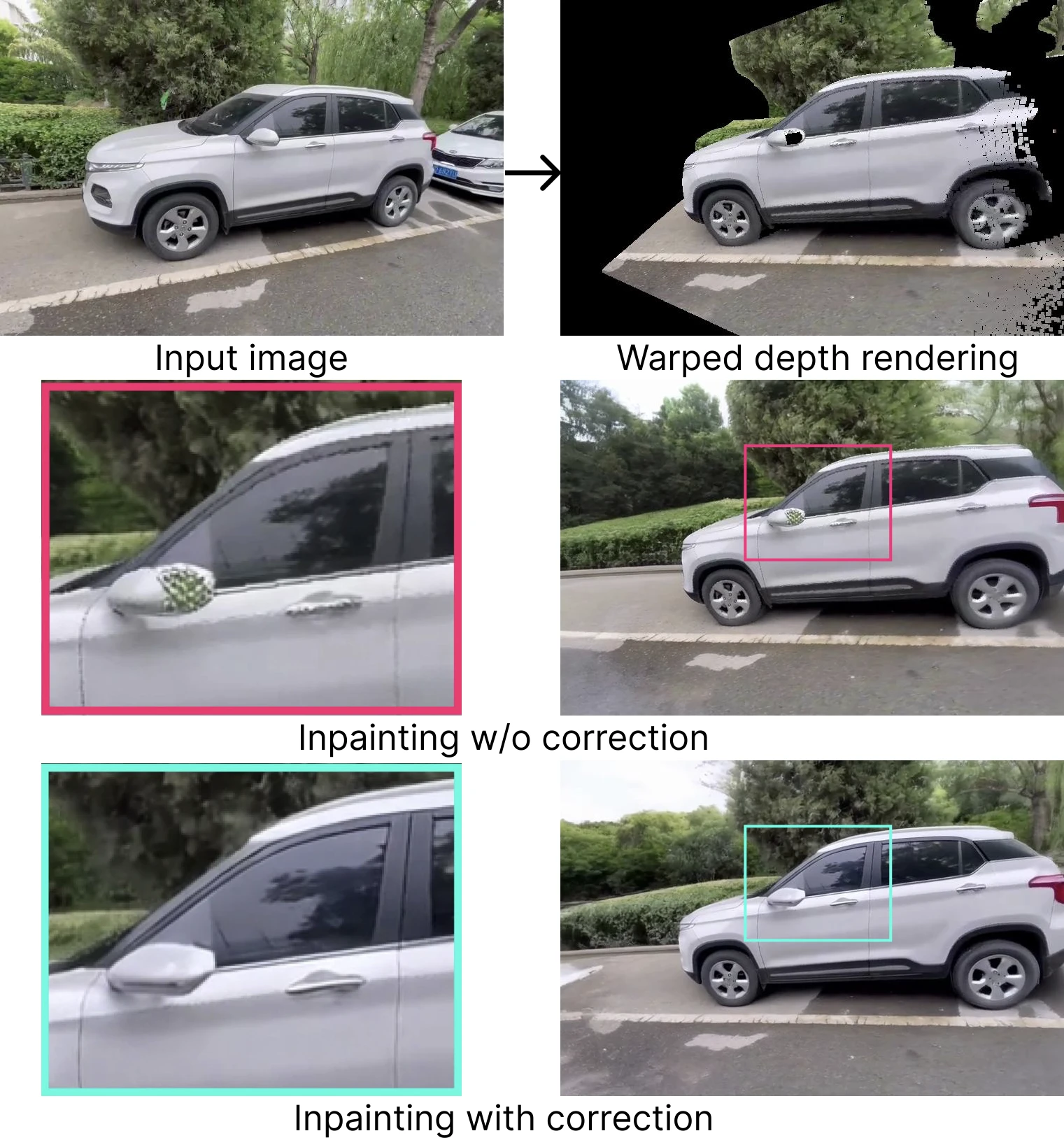
What stands out in the results
The strongest pattern is not just image quality, but consistency. The method performs especially well on perceptual metrics and out-of-domain benchmarks, which suggests the pretraining objective learns a reusable geometric prior rather than simply memorizing dataset-specific camera behavior.
| Task / Benchmark | Highlight | Takeaway |
|---|---|---|
| Single-view NVS · Tanks and Temples | Best LPIPS, DISTS, and FID among generative baselines | Sharper and more coherent generations than prior generative NVS methods |
| Two-view interpolation · OOD datasets | Strongest perceptual and distribution metrics overall | Generalizes well even outside the training distribution |
| 3D consistency check | Lower Chamfer distance than ViewCrafter | Generated views reconstruct into cleaner geometry |
| Video editing | Only method that convincingly propagates large edits through the clip | The completion objective transfers naturally to edit propagation |


Project Results
Image-conditioned view generation
The clips below show this project generating camera motion from a single input image across indoor scenes, outdoor scenes, object-centric captures, and real-world trajectories.
Venice
Dome Rotation
Tanks and Temples Playground
Mip-NeRF 360 Garden
Library Forward
DL3DV Validation
White Car
Zoom In
Mip-NeRF Bonsai
Mip-NeRF Kitchen
Mip-NeRF Room
Mip-NeRF 360 Flower
Bicycle Evaluation
Tennis Court Pullback
Two-View Interpolation
Long-baseline interpolation
These wide clips show synthesized intermediate viewpoints between two observed endpoint images.
Barn
Car
House
Consistent Video Editing
Video inpainting with consistency
Each row starts from an original video and a single edited first frame. The model propagates the edit through the sequence while adapting it to motion and viewpoint changes.
Statue with teddy bear edit
Input video

Edited first frame
Inpainted output
Statue with campfire edit
Input video

Edited first frame
Inpainted output
Palace with cat edit
Input video

Edited first frame
Inpainted output
The bigger picture
The objective design suggests a broader pattern: if a model needs to behave like a geometric reasoner, it can help to repeatedly train it on inverse problems that require geometric consistency.
3D consistency is not inserted by hand. It is induced by repeatedly asking the model to reconcile partial multi-view evidence.
Limits
Still a video backbone
The model generates consecutive frames, not arbitrary unordered camera views. That limits true free-form multiview synthesis.
Warping is the bottleneck
Large scenes, strong disocclusions, and severe depth errors remain hard because the inference pipeline still begins with monocular depth warping.